- La irrupción de Grokipedia plantea el dilema de una enciclopedia generada por IA sin revisiones humanas frente al modelo comunitario de Wikipedia.
- Los grandes modelos de lenguaje ya empiezan a citar Grokipedia, alimentando riesgos de sesgo, desinformación silenciosa y grooming de LLM.
- Wikipedia responde reforzando su comunidad, usando la IA como apoyo y no como sustituto, y endureciendo el control contra textos generados por máquinas.
- La caída de tráfico humano y el auge de los chatbots reconfiguran quién controla el acceso al conocimiento y bajo qué reglas de transparencia.

La idea de una enciclopedia sin editores humanos suena, a primera vista, a ciencia ficción eficiente: textos siempre actualizados, cero discusiones internas, ningún voluntario quemado tras revertir vandalismos. Pero cuando se mira de cerca, el modelo despierta más dudas que entusiasmos. Entre Grokipedia, Wikipedia y los grandes chatbots, lo que está en juego no es solo quién escribe los artículos, sino quién define qué consideramos conocimiento fiable.
En los últimos años, se ha abierto una brecha muy clara entre el enfoque de plataformas humanas como Wikipedia y el de proyectos basados casi por completo en modelos de lenguaje. Wikipedia, con todas sus imperfecciones, se ha convertido en un experimento social gigantesco de deliberación pública; Grokipedia, en cambio, representa la apuesta por una enciclopedia donde la IA toma el mando y las personas quedan relegadas a un papel casi testimonial. La fricción entre ambos modelos no es un debate técnico, sino profundamente político e informativo.
Grokipedia: la enciclopedia que presume de no tener editores humanos
Cuando Elon Musk presentó Grokipedia como alternativa a Wikipedia, la promesa era llamativa: una enciclopedia generada de forma automática por el modelo Grok de xAI, sin una comunidad humana editando línea a línea. Según se ha contado en medios como Gizmodo y otros, Musk llevaba tiempo descalificando a Wikipedia como “Wokipedia”, acusándola de sesgos ideológicos y defendiendo la necesidad de una enciclopedia alineada con una sensibilidad política distinta.
El funcionamiento básico de Grokipedia es sencillo de explicar: la plataforma se lanzó con más de 885.000 artículos creados por inteligencia artificial, tomando como punto de partida contenidos de Wikipedia reutilizados gracias a las licencias abiertas. A partir de ahí, la propia IA se encarga de actualizar y ampliar textos, sin un sistema comunitario de edición directa como el que caracteriza a Wikipedia.
El diseño es minimalista, con un buscador y artículos relativamente más cortos y esquemáticos que los de Wikipedia. No hay notas al pie detalladas ni citas en línea que permitan seguir el rastro de cada afirmación hasta una fuente verificable. Los usuarios solo pueden pedir cambios mediante solicitudes que procesa el modelo Grok, de manera que el filtro último sigue siendo algorítmico, no comunitario.
Todo esto contrasta con la filosofía de Wikipedia, donde cualquier persona puede editar y cada cambio queda registrado en un historial público que permite revisar quién añadió qué, cuándo y por qué. En Grokipedia, en cambio, la lógica se parece más a una imprenta automática que no descansa: el sistema genera texto sin pasar por las capas de conflicto, revisión y consenso que caracterizan al modelo wikipedista.
El propio Musk ha defendido que la versión 0.1 de Grokipedia ya superaría en calidad a Wikipedia, a la vez que habla de “purga de propaganda” sin aclarar qué criterios usa la IA para decidir qué es propaganda y qué no. Esa opacidad sobre quién define el marco ideológico es uno de los grandes puntos de fricción con quienes ven la enciclopedia como un espacio de deliberación abierta y trazable.
Cuando los chatbots empiezan a citar Grokipedia
La polémica dio un salto de nivel cuando se detectó que los últimos modelos de conversación empezaban a citar Grokipedia como fuente. The Guardian relató pruebas en las que GPT‑5.2, de OpenAI, referenciaba artículos de Grokipedia al responder preguntas sobre cuestiones tan dispares como estructuras políticas iraníes o académicos británicos; Gizmodo aseguró haber reproducido comportamientos similares con consultas cercanas.
Que un chatbot cite una web no significa, por sí solo, que lo que dice sea falso. Pero sí es una señal de que ese contenido está entrando en el circuito de referencias automatizadas. Es como si en una biblioteca alguien empezara a colocar, sin mucho control, libros de origen dudoso en la mesa de recomendaciones: algunas páginas pueden ser correctas, pero el umbral de confianza cambia.
El detalle más inquietante es que Grokipedia no aparecía tanto en temas donde ya se la había señalado por enfoques engañosos, sino en asuntos más específicos o poco transitados. Precisamente en esas áreas menos visibles suele haber menos vigilancia periodística, menos especialistas y menos textos de calidad compitiendo por posicionarse. Ahí, cualquier contenido que parezca enciclopédico tiene más posibilidades de colarse en el radar de los modelos.
OpenAI, por su parte, ha defendido que sus modelos se apoyan en un abanico amplio de fuentes públicas y que aplican filtros de seguridad para evitar enlazar contenidos claramente dañinos, mostrando citas para que el usuario pueda comprobar el origen de la información. Sobre el papel, la transparencia ayuda; en la práctica, muchos lectores interpretan la mera presencia de una referencia como un sello de calidad, sin pararse a evaluar si esa fuente merece o no confianza.
No es un caso aislado: usuarios han reportado menciones similares en Claude, el chatbot de Anthropic. Cuando varios sistemas diferentes empiezan a enlazar la misma enciclopedia generada automáticamente, el problema deja de ser anecdótico y se transforma en un riesgo sistémico para el ecosistema de información.
Sesgo que no grita: cómo cambia todo al cambiar el marco
Buena parte del debate sobre Grokipedia no gira en torno a errores factuales groseros, sino a encuadres más suaves o más duros según el tema. Gizmodo y otros medios han señalado ejemplos en los que los sucesos del 6 de enero de 2021 en el Capitolio de Estados Unidos se describen con un lenguaje más edulcorado que el que usa Wikipedia, que opta por un tono más contundente y contextualizado.
Lo mismo sucede con la forma de presentar determinados grupos políticos: donde Wikipedia habla abiertamente de extremismo, odio o ideologías concretas, Grokipedia tiende —en los casos señalados— a usar formulaciones del tipo “defensa de la soberanía nacional” u otras expresiones más neutras en apariencia. No siempre se trata de mentiras en sentido estricto, sino de decisiones léxicas que empujan al lector en una dirección u otra.
En la vida diaria lo hacemos constantemente: no es igual decir “me equivoqué” que hablar de “un ligero desajuste”, aunque se refieran al mismo hecho. En un chatbot, esa inclinación importa aún más porque el usuario suele leer la respuesta entera como un bloque coherente, no como un mosaico de matices que se puedan auditar palabra a palabra.
Especialmente delicado es el tratamiento de teorías conspirativas como la del “Gran Reemplazo”. Wikipedia la etiqueta de forma explícita como teoría conspirativa, mientras que los encuadres más tibios pueden dar la sensación de que se trata de una idea debatible en igualdad de condiciones con explicaciones basadas en evidencias. Ahí el impacto es doble: no solo informativo, sino social, porque la desinformación más efectiva suele llegar con envoltorio académico, no con mayúsculas y exclamaciones.
Este tipo de sesgo “susurrado” resulta especialmente peligroso cuando los motores de búsqueda y los chatbots lo reproducen sin indicar que se trata de una interpretación controvertida. Lo que se presenta como neutralidad puede esconder una toma de partido invisible para gran parte de los usuarios.
Grooming de modelos y model collapse: cuando la web se retroalimenta de IA
Investigadores llevan tiempo alertando sobre el llamado grooming de LLM: la estrategia de inundar internet con contenido generado por modelos de lenguaje para influir en lo que otros modelos aprenderán más adelante o en lo que recuperarán cuando busquen fuentes. No hace falta imaginar una conspiración coordinada; basta con la realidad económica de que publicar miles de textos sintéticos es baratísimo y hay incentivos políticos, comerciales e ideológicos para hacerlo.
Una metáfora útil es la de una cocina industrial: si la despensa se llena de ingredientes ultra procesados y baratos, el chef puede seguir sacando platos con buena pinta, pero el valor nutricional se resiente. Del mismo modo, los sistemas que indexan y citan contenidos corren el riesgo de alimentarse de una web cada vez más saturada de texto fabricado por máquinas, en especial cuando se trata de temas poco cubiertos por medios serios.
A esto se suma el fenómeno llamado model collapse, descrito en estudios recientes: si los modelos se entrenan cada vez más sobre datos producidos por otros modelos, la calidad global del sistema empieza a degradarse. La imagen clásica es la de las fotocopias sucesivas: cada nueva copia pierde detalle y acumula artefactos, hasta que el original resulta irreconocible.
En el terreno del lenguaje, esto se traduce en menos diversidad de estilos e ideas, peor rendimiento en casos minoritarios y errores que se retroalimentan generación tras generación. El investigador Ilia Shumailov y otros han explicado que primero se pierden los matices y empeora el desempeño en datos poco representados; después, el sistema puede llegar a “romperse” de forma más amplia.
Enciclopedias automáticas como Grokipedia encajan perfectamente en este escenario: son, a la vez, producto y alimento para la IA. Producen grandes volúmenes de texto que los modelos pueden rastrear y reutilizar, y a la vez se apoyan en esos mismos modelos para seguir generando material. Sin diques claros, la web corre el riesgo de convertirse en un circuito cerrado donde los humanos apenas actúan como espectadores.
Wikipedia: un experimento social basado en fricción humana
Frente a ese panorama, Wikipedia representa casi un anacronismo funcional. Lanzada en 2001, creció al calor de la llamada web 2.0: usuarios que dejan de ser audiencia pasiva y se convierten en participantes, con portales basados en colaboración más que en consumo. Veinticinco años después, la enciclopedia en línea se ha consolidado como uno de los experimentos sociales más influyentes de la era digital.
La clave no es que Wikipedia sea perfecta, porque no lo es; su fuerza reside en que expone sus conflictos y sus límites. Detrás de cada entrada aparentemente neutra hay un baile complejo de decisiones humanas: voluntarios que revisan fuentes, discuten enfoques, deciden qué es relevante y aplican políticas como la verificabilidad o la neutralidad de punto de vista.
Historias como la de Jimmy Wales intentando documentar una carnicería en Gugulethu, Sudáfrica, ilustran bien el modelo. Sus ediciones fueron revertidas por otros usuarios que ponían en duda la relevancia del comercio. El desenlace no fue que se impusiera la autoridad del fundador, sino que se dejó constancia del desacuerdo. En Wikipedia, ni siquiera el poder simbólico del creador queda al margen del escrutinio público.
Leer el historial de una página puede llegar a ser más instructivo que el texto actual: ahí se ven guerras de ediciones, acuerdos temporales, cambios de criterio. No es casual que académicos hayan usado esos historiales para estudiar disputas científicas —como las relativas a la edición genética con Crispr— o procesos políticos como la revolución egipcia de 2011. No solo se almacena conocimiento: se documenta cómo se construye.
La escala del esfuerzo humano es abrumadora. Miles de millones de personas visitan Wikipedia cada año y más de cien millones de usuarios han realizado alguna edición a lo largo del tiempo. Todo eso sin publicidad invasiva, sin venta masiva de datos personales y con una fundación —Wikimedia— sostenida principalmente por donaciones y algunos acuerdos de licencias para reutilización a gran escala, incluidos los que sirven para entrenar sistemas de IA.
IA sí, pero al servicio de los voluntarios: la estrategia de Wikimedia
La Fundación Wikimedia ha dejado claro que su prioridad es reforzar el papel del voluntariado y no sustituirlo. Su nueva estrategia de IA va precisamente en esa dirección: aplicar modelos de inteligencia artificial allí donde son especialmente útiles para apoyar a las personas, no para expulsarlas del proceso editorial.
Entre los objetivos declarados están ayudar a los patrulleros y moderadores con flujos de trabajo asistidos por IA que automaticen tareas tediosas (como detectar vandalismo o patrones sospechosos), mejorar la forma de encontrar información dentro de la propia Wikipedia para que los editores dediquen más tiempo a deliberar y consensuar y menos a pelearse con la interfaz, y facilitar la traducción y adaptación de contenidos entre distintos idiomas.
También se busca hacer más fácil la entrada a nuevas personas voluntarias, con sistemas de mentoría apoyados en IA que orienten los primeros pasos. Todo ello con unos principios claros: enfoque centrado en humanos, prioridad al software abierto o con valores abiertos, transparencia sobre cómo se usan los modelos y una atención especial a la multilingualidad, que es uno de los rasgos fundamentales de Wikipedia.
Ese equilibrio no está exento de tensiones. Un ejemplo fue el experimento “Simple Article Summaries”, que mostraba en la parte superior de algunos artículos resúmenes generados por IA marcados como “no verificados”, creados con modelos Aya de Cohere. La iniciativa pretendía hacer más accesibles las páginas complejas, pero la comunidad reaccionó con un rechazo masivo.
Comentarios como “muy mala idea”, “mi más firme rechazo” o directamente “puaj” resumen el clima de opinión de muchos editores. La Fundación decidió pausar el experimento tras la avalancha de críticas, subrayando que cualquier función futura de este tipo requerirá participación activa de la comunidad y mecanismos de moderación humana. No es un portazo a la IA, sino una pausa táctica y un recordatorio de que, en Wikipedia, las decisiones editoriales no se toman por decreto.
Cómo combate Wikipedia el contenido generado por IA de baja calidad
El auge de herramientas generativas ha inundado la red de textos plausibles pero erróneos, y Wikipedia no ha salido indemne. Cada vez se detectan más artículos, referencias y traducciones sospechosos de haber sido generados por modelos sin suficiente revisión humana. Para muchos editores veteranos, limpiar esa marea de escombros consume horas y erosiona la motivación.
Ante esta situación, la comunidad ha impulsado medidas concretas. Una de las más contundentes es un protocolo de borrado rápido para artículos claramente generados por IA sin revisión, que permite a los administradores eliminar textos que presenten ciertos indicios (estructuras típicas de chatbots, referencias inventadas, enlaces muertos en masa, tono promocional poco enciclopédico) sin tener que pasar por los siete días de discusión habitual.
Dentro del proyecto interno WikiProject AI Cleanup, un grupo de voluntarios mantiene y actualiza una lista de patrones lingüísticos y de formato característicos de los textos automáticos: uso recurrente de ciertas fórmulas, abuso de guiones largos, redacción dirigida en segunda persona al lector, bibliografías imposibles de verificar, etc. Eso permite a otros editores identificar más rápido el contenido problemático.
La propia Fundación Wikimedia combina esta vigilancia humana con herramientas automáticas que ayudan a detectar vandalismo y comportamientos anómalos. El director de producto, Marshall Miller, ha descrito el papel de la comunidad como un “sistema inmune” en evolución constante: cuando aparecen nuevas amenazas —ya sean campañas de desinformación o avalanchas de texto sintético—, el cuerpo editorial se adapta con políticas y mecanismos técnicos.
Además, se están desarrollando funcionalidades como Edit Check, destinada a guiar a los editores novatos recordándoles la necesidad de incluir citas fiables o de mantener un tono neutral. Una futura función llamada Paste Check preguntará a quienes peguen grandes bloques de texto si son de su autoría, con propuestas en la comunidad para pedir que se declare explícitamente qué fragmentos han sido generados por IA. No se trata de prohibir la herramienta, sino de hacer visible su uso y someterla al mismo estándar de verificación que a cualquier otro contenido.
Traducciones automáticas, errores silenciosos y el caso OKA
Otro frente abierto es el de las traducciones asistidas por IA. En un caso reciente, algunos editores de Wikipedia comenzaron a revisar traducciones nuevas y observaron frases que no aparecían en las fuentes citadas, referencias mal asignadas y párrafos basados en material irrelevante o no relacionado.
Según informó 404 Media y otros medios, estos problemas estaban vinculados a un proyecto impulsado por la organización sin ánimo de lucro Open Knowledge Association (OKA), que buscaba ampliar la presencia de contenidos entre idiomas apoyándose en modelos de lenguaje para acelerar el trabajo. En un borrador sobre la familia real francesa La Bourdonnaye, por ejemplo, una referencia a un libro y una página concreta resultó ser errónea cuando el editor Ilyas Lebleu (Chaotic Enby) revisó la fuente.
Al profundizar en el análisis, se detectaron otros fallos: referencias intercambiadas, frases sin respaldo documental y párrafos que parecían fabricados a partir de material tangencial o mal interpretado. La duda clave era cuántos de esos errores habían llegado a colarse en artículos ya publicados y cuántos se habían frenado en fase de borrador, algo difícil de cuantificar con precisión solo a partir de los casos documentados.
La respuesta de la comunidad fue endurecer las reglas. Se estableció que los traductores vinculados a OKA que acumulen cuatro advertencias por contenido no verificable en seis meses podrían ser bloqueados automáticamente si reinciden. Además, el contenido añadido por un traductor que termine bloqueado puede eliminarse de forma preventiva, salvo que otro editor con buena reputación se comprometa a revisarlo en detalle.
Desde OKA, su fundador Jonathan Zimmermann ha defendido que los colaboradores trabajan con pago por hora, sin objetivos fijos de producción, y que “los errores ocurren”, pero que el proceso incluye revisión humana y verificación de fuentes. Tras las críticas, la organización anunció una segunda capa de revisión con otro modelo de IA y la posible implementación de revisiones por pares. Aun así, el episodio ha servido para subrayar que una traducción rápida impulsada por modelos puede introducir distorsiones sutiles que pasan más desapercibidas que un error grosero.
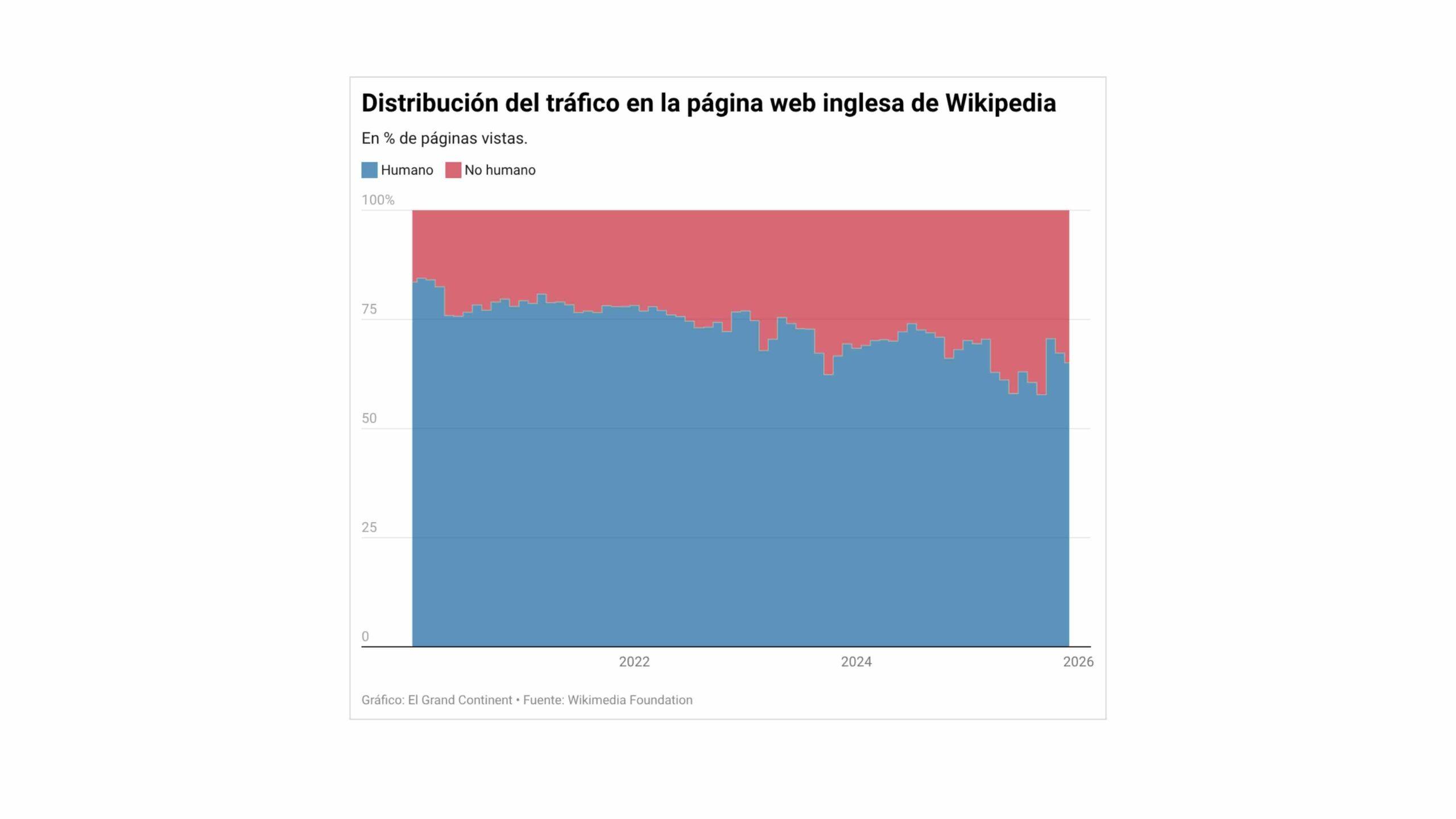
Caída de tráfico humano, auge de los bots y nuevas licencias para la IA
Todo este debate se produce mientras cambia el modo en que la gente accede a la información y la experiencia de búsqueda. Wikipedia, como muchos otros sitios, sufre una caída notable de tráfico humano ligada al uso masivo de chatbots. En lugar de acudir a un buscador que derive hacia páginas web, cientos de millones de personas formulan directamente sus preguntas a sistemas como ChatGPT, Gemini o Le Chat.
En ese contexto, la Fundación Wikimedia ha observado un “aumento significativo” de las consultas a sus servidores, pero gran parte de ese incremento no procede de usuarios de carne y hueso, sino de robots de scraping que recolectan datos para entrenar modelos. La mayoría de webs que sirven como materia prima para la IA no reciben compensación alguna; hasta hace poco, Wikipedia era en gran medida uno de esos grandes suministradores gratuitos.
Esto empezó a cambiar con la firma de acuerdos de licencia con empresas como Amazon, Meta, Perplexity, Microsoft o Mistral AI. A partir de estos convenios, las compañías pagarán por acceder y reutilizar el contenido de la enciclopedia para sus modelos, de manera más ordenada y con ciertas garantías. No va a revertir por sí solo la caída de tráfico humano, pero sí supone un paso hacia un modelo en el que los robots de scraping dejen de operar como meros free riders.
Los datos globales apuntan a un cambio de hábitos significativo: el tráfico en webs de referencia, científicas y educativas ha caído alrededor de un 10‑15% interanual en algunos casos, mientras que grandes medios anglófonos pierden entre un 18% y un 45% de visitas, según informes recientes. En paralelo, los sitios de chatbots registran crecimientos de doble dígito; ChatGPT, por ejemplo, ha alcanzado miles de millones de visitas mensuales con incrementos anuales en torno al 70%.
En este paisaje emergen competidores como Grokipedia o la alternativa rusa Ruwiki, que se presentan como enciclopedias “sin sesgo”. En la práctica, sin embargo, ambas se apoyan fuertemente en contenido ya existente: Grokipedia mediante generación basada en textos de Wikipedia, y Ruwiki mediante una bifurcación de la versión rusa de la enciclopedia original. El resultado es una paradoja: proyectos que critican a Wikipedia mientras dependen de ella para poblar sus propias bases de datos.
La gran incógnita es si, en un entorno dominado por resúmenes automáticos en la página de resultados del buscador y respuestas directas de chatbots, Wikipedia podrá mantener su centralidad informativa sin sacrificar el criterio humano que la distingue. La respuesta no llegará de la noche a la mañana, pero marcará en buena parte el rumbo del conocimiento abierto en las próximas décadas.
Todo este choque de modelos —Grokipedia y sus textos generados sin editores, los chatbots que empiezan a citarla, la comunidad wikipedista que endurece filtros para frenar la “basura de IA” mientras adopta herramientas que le ahorran trabajo mecánico— nos deja un recordatorio incómodo: la calidad de la información no depende solo de la potencia de los algoritmos, sino de cuánta fricción humana aceptamos mantener en el sistema. Renunciar a debates, historiales públicos y revisiones puede hacer que todo parezca más rápido y terso, pero también abre la puerta a un internet donde la verosimilitud manda más que la verdad y donde los humanos dejan de ser autores para convertirse, poco a poco, en meros consumidores de lo que las máquinas se cuentan unas a otras.
