- La memoria HBM ofrece un ancho de banda masivo con menor consumo gracias a su diseño 3D apilado y buses muy anchos.
- Su evolución (HBM, HBM2, HBM2E, HBM3 y HBM-PIM) ha incrementado capacidad, velocidad y eficiencia para IA y supercomputación.
- Frente a GDDR, HBM es más eficiente y compacta, pero mucho más cara y compleja de fabricar, por lo que se reserva a GPU de gama extrema.
- HBM resulta clave en aceleradores como NVIDIA H100 o AMD Instinct para manejar cargas de trabajo de IA y HPC a gran escala.

Cuando se habla de rendimiento extremo en tarjetas gráficas, IA y supercomputación, uno de los factores clave no es solo la potencia de la GPU, sino el tipo de memoria que la acompaña. En los últimos años, la memoria HBM (High Bandwidth Memory) se ha convertido en la pieza estrella para mover cantidades brutales de datos con un consumo de energía sorprendentemente bajo.
Lejos de ser una simple evolución de la RAM tradicional, la memoria HBM es una arquitectura distinta, pensada desde cero para ofrecer ancho de banda masivo, factor de forma mínimo y gran eficiencia. A continuación vas a encontrar una explicación a fondo de qué es HBM, cómo funciona, en qué se diferencia de GDDR, cómo ha ido evolucionando (HBM, HBM2, HBM2E, HBM3 y variantes PIM) y por qué se ha vuelto imprescindible en GPU como NVIDIA H100 o AMD Instinct MI300X.
Qué es la memoria HBM y en qué se diferencia de otras DRAM

La memoria HBM, siglas de High Bandwidth Memory, es un tipo de memoria DRAM de alta velocidad diseñada para ofrecer un ancho de banda enorme en un espacio físico muy reducido y con un consumo mucho menor que DDR4 o GDDR5/GDDR6. En lugar de colocar varios chips alrededor del procesador, como ocurre con la memoria GDDR, HBM se organiza en pilas de chips DRAM apilados verticalmente sobre un mismo sustrato.
Cada pila HBM está formada por varias matrices (dies) de DRAM colocadas una encima de otra, normalmente hasta ocho capas en las primeras generaciones, aunque los estándares más nuevos permiten aún más niveles. Estas matrices están unidas entre sí mediante vías a través de silicio (TSV) y micro-soldaduras, lo que permite comunicar las capas verticalmente con una latencia muy baja y miles de conexiones en paralelo.
Para poder conectar estas pilas de memoria con la GPU o la CPU, se utiliza habitualmente un interposer de silicio, una especie de “puente” de alta densidad que se coloca bajo la GPU y las pilas de HBM. Este interposer permite rutas de datos muy cortas y anchas, con muchos más pines que los que se podrían sacar por una PCB convencional, a costa de incrementar de forma notable la complejidad y el coste de fabricación del encapsulado.
A diferencia de la DRAM tradicional, donde se priorizan frecuencias altas con buses relativamente estrechos, la filosofía de HBM es la contraria: frecuencia moderada, bus extremadamente ancho. De este modo, se consigue un ancho de banda total brutal sin necesidad de disparar las velocidades de reloj, lo que se traduce en menos calor y mejor eficiencia energética.
Cómo se organiza internamente una pila de memoria HBM
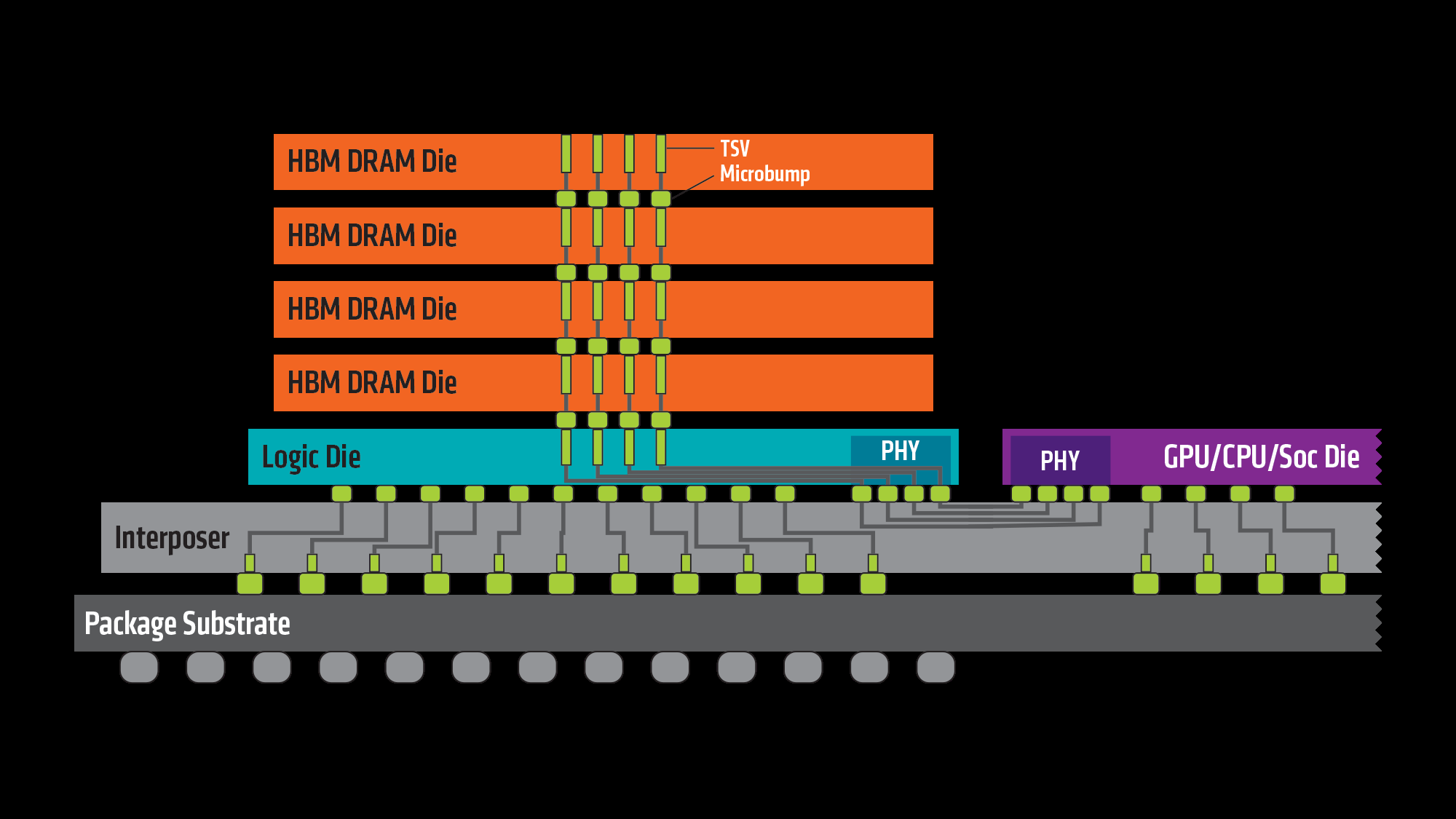
La DRAM HBM está estrechamente acoplada al chip principal (GPU, CPU o acelerador específico) mediante una interfaz de memoria distribuida por canales. Cada pila HBM se divide en varios canales totalmente independientes entre sí, que pueden funcionar sin estar sincronizados unos con otros, lo que ayuda a paralelizar las operaciones de lectura y escritura.
En la primera generación de HBM, una pila típica de cuatro capas DRAM (conocida como 4‑Hi) ofrece ocho canales de memoria, cada uno de 128 bits. Eso da como resultado un bus total de 1024 bits por pila. Esta estructura multicanal permite que el controlador de memoria reparta el tráfico entre muchos caminos en paralelo, reduciendo cuellos de botella y mejorando el aprovechamiento del ancho de banda.
La interfaz de HBM funciona con un reloj diferencial de unos 500 MHz, en el que los comandos se registran en el flanco de subida de la señal. Cada canal trabaja en modo DDR (Double Data Rate), es decir, transfiere datos tanto en el flanco de subida como en el de bajada de la señal de reloj. Con una tasa típica de 1 gigatransferencia por segundo (1 GT/s) por pin en la primera versión, una pila de 1024 bits puede alcanzar alrededor de 128 GB/s de ancho de banda.
En cuanto a capacidad, las primeras pilas HBM permitían hasta 4 GB por encapsulado. Combinando varias pilas alrededor de una misma GPU, es posible montar buses de miles de bits. Por ejemplo, una tarjeta con cuatro pilas HBM de 1024 bits cada una disfruta de un bus de 4096 bits, algo que deja muy atrás los 512 bits máximos típicos de GDDR5 de aquella época.
Origen y desarrollo de la memoria HBM
El concepto de HBM empezó a gestarse sobre 2008, con AMD como impulsora principal. La compañía se encontraba con una limitación clara: necesitaba más ancho de banda de memoria para alimentar sus GPU, pero seguir aumentando la frecuencia y el número de chips GDDR alrededor del encapsulado llevaba a consumos, temperaturas y tamaños de PCB poco sostenibles.
El objetivo de AMD era diseñar un tipo de memoria que redujera el consumo y el espacio ocupado, al tiempo que proporcionara un salto significativo en el ancho de banda disponible. Para lograrlo, la empresa trabajó en distintos métodos de apilamiento de matrices DRAM en 3D, bajo la dirección de Bryan Black, uno de los ingenieros clave del proyecto.
Desde el principio fue evidente que AMD no podía hacerlo sola, así que se apoyó en varios socios de la industria. Uno de los aliados principales fue SK Hynix, que ya tenía experiencia en memorias apiladas en 3D. También participaron empresas especializadas en interposers, como UMC, y en procesos de encapsulado avanzados, como Amkor Technology y ASE, indispensables para montar todo el conjunto GPU + HBM sobre el mismo sustrato.
En 2013, SK Hynix consiguió fabricar el primer chip de memoria HBM funcional. Ese mismo año, en octubre, la organización JEDEC adoptó HBM como estándar oficial, tras una propuesta conjunta de AMD y SK Hynix presentada en 2010. La producción en volumen de estas memorias comenzó en 2015, coincidiendo con su llegada a productos comerciales.
La primera GPU que llevó HBM al mercado fue la familia AMD Fiji, lanzada en junio de 2015. Tarjetas como la Radeon R9 Fury demostraron que era posible lograr un gran ancho de banda con PCBs más compactas y sin disparar el consumo, aunque a costa de un coste de fabricación significativamente más alto que el de las soluciones basadas en GDDR.
Evolución de las generaciones de memoria HBM
Tras el debut de HBM de primera generación, la tecnología no dejó de avanzar, dando lugar a varias revisiones con más capacidad y mayor rendimiento. Cada salto ha ido puliendo la fórmula inicial, manteniendo la idea básica del apilamiento 3D y el bus ancho, pero escalándola a niveles cada vez más extremos.
HBM (primera generación)
La primera versión de HBM fue la que se integró en las GPU AMD Fiji. Ofrecía pilas de hasta cuatro capas DRAM, con dos canales de 128 bits por capa, sumando ocho canales y 1024 bits por pila. El ancho de banda por pila rondaba los 128 GB/s, con una capacidad máxima típica de 4 GB por stack y hasta 16 GB en total en una tarjeta gráfica con cuatro pilas.
En comparación, una configuración de memoria GDDR5 estándar proporcionaba 32 bits por chip y hasta 16 chips en paralelo, dando un bus máximo de 512 bits. Aunque las frecuencias de GDDR5 eran superiores, el enfoque de HBM con un bus ocho veces más ancho compensaba de sobra, ofreciendo un salto claro en ancho de banda a frecuencias más contenidas.
HBM2
La siguiente gran iteración fue HBM2, que duplicó aproximadamente la velocidad de transferencia por pin con respecto a la primera HBM, llegando hasta 2 GT/s. Manteniendo el bus de 1024 bits por pila, esto permite alcanzar un ancho de banda de unos 256 GB/s por encapsulado, más del doble de lo que ofrecía la primera generación.
Además del incremento en velocidad, HBM2 elevó la capacidad por pila hasta los 8 GB. Esto hace posible configuraciones con múltiples stacks que suman fácilmente 64 GB de memoria HBM2 en una sola GPU o acelerador, algo clave para cargas de trabajo de IA y HPC que manejan modelos y conjuntos de datos muy voluminosos.
En enero de 2016, Samsung anunció la producción temprana de HBM2, mientras que JEDEC la aprobaba como nuevo estándar. Ese mismo año, NVIDIA lanzó la Tesla P100, la primera solución comercial en integrar HBM2, orientada a computación de alto rendimiento. Poco después, Intel introdujo sus aceleradoras Xeon Phi con memorias HCDRAM, una variante basada en conceptos similares a HBM pero desarrollada por Micron.
HBM2E
Conforme las necesidades de rendimiento siguieron creciendo, se presentó una actualización conocida como HBM2E, pensada como una evolución sobre HBM2 más que como un estándar completamente nuevo. Esta revisión incrementa la velocidad efectiva hasta unos 2,5 Tbit/s por pila, lo que se traduce en un ancho de banda de aproximadamente 307 GB/s por stack.
Otra de las mejoras importantes de HBM2E es la posibilidad de apilar hasta 12 capas de memoria (12‑Hi), lo que permite alcanzar capacidades de 24 GB por pila. Gracias a esta densidad, una GPU o CPU con varias pilas HBM2E puede llegar a ofrecer cantidades de memoria enormes pegadas literalmente al chip de cálculo.
Fabricantes como Samsung y SK Hynix han desarrollado sus propias implementaciones de HBM2E. Samsung presentó su variante denominada Flashbolt HBM2E, con ocho matrices por pila, 16 GB de capacidad y un ancho de banda de hasta 3,2 GT/s por pin, lo que se traduce en más de 400 GB/s por stack de memoria. SK Hynix, por su parte, anunció pilas de 16 GB con velocidades de hasta 3,6 GT/s, ofreciendo alrededor de 460 GB/s de ancho de banda por pila.
HBM3 y HBMnext
A finales de 2020, Micron adelantó la siguiente gran evolución bajo el nombre provisional de HBMnext, que más tarde se consolidaría como HBM3. Esta generación supone un salto considerable frente a HBM2E, con el objetivo de responder a las demandas de GPU de centros de datos y aceleradores para IA a gran escala.
HBM3 está diseñada para ofrecer hasta unos 665 GB/s de ancho de banda por pila, más del doble que HBM2E en muchos casos. Además, el estándar contempla pilas de hasta 16 capas (16‑Hi) y capacidades de 64 GB por stack, con lo que una sola GPU equipada con varias pilas puede disponer de centenares de gigabytes de memoria extremadamente rápida junto al chip.
Para mejorar aún más la eficiencia de interconexión, algunas implementaciones de HBM3 han licenciado tecnologías como la interconexión híbrida DBI Ultra 2.5D/3D, desarrollada por Xperi, que optimiza la forma en la que se unen las diferentes capas y el interposer, reduciendo resistencias y mejorando la calidad de señal a altas velocidades.
En el mercado actual, la memoria HBM3 se ha popularizado especialmente en GPU como la NVIDIA H100, que cuenta con un bus de 5120 bits y un ancho de banda agregado de más de 2 TB/s, o el AMD Instinct MI300X, que llega todavía más lejos con un bus de 8192 bits y más de 5,3 TB/s de ancho de banda de memoria. Además, NVIDIA ha introducido HBM3E en productos como GH200 y H200, afinando todavía más la velocidad efectiva.
HBM con procesamiento en memoria (HBM-PIM)
En febrero de 2021, Samsung dio un paso distinto al anunciar una versión de HBM con procesamiento en memoria (PIM, Processing In Memory). La idea es integrar dentro de cada banco de DRAM un pequeño motor de cómputo especializado en tareas de inteligencia artificial, de forma que parte del procesamiento se realice directamente donde residen los datos.
Con este enfoque, se pueden ejecutar operaciones de IA de forma paralela dentro de las propias pilas de memoria, minimizando el movimiento de datos entre la memoria y la GPU/CPU. Esto no solo acelera ciertas cargas de trabajo, sino que reduce drásticamente el consumo energético asociado al tráfico de memoria, uno de los grandes orígenes de calor y gasto en sistemas de alto rendimiento.
Según Samsung, esta memoria HBM-PIM puede llegar a duplicar el rendimiento del sistema y reducir el consumo de energía en más de un 70 %, sin necesidad de modificar el resto del hardware o el software de la plataforma, ya que el funcionamiento hacia el exterior se mantiene compatible con las interfaces estándar de HBM.
Diferencias entre memoria HBM y memoria GDDR
Para entender mejor el papel de HBM, conviene compararla con su principal alternativa en el mundo de las GPU: la memoria GDDR. Esta familia de memorias (GDDR5, GDDR6, GDDR6X, GDDR7, etc.) se basa en la misma filosofía que la DDR de sistema, pero adaptada a las necesidades de alto ancho de banda de las tarjetas gráficas.
La GDDR se suelda directamente en la PCB alrededor de la GPU. Cada chip suele tener un bus relativamente estrecho (por ejemplo, 32 bits), y el ancho de banda total se consigue sumando varios chips en paralelo y subiendo la frecuencia de reloj hasta cifras muy altas. El estándar GDDR6, por ejemplo, puede alcanzar velocidades de hasta 16 Gb/s por pin, mientras que su derivada GDDR6X, utilizada en algunas GPU de NVIDIA, llega a unos 21 Gb/s por pin utilizando modulación PAM4.
El ancho de bus total en GPU modernas con GDDR6 o GDDR6X suele situarse en torno a los 256 a 384 bits. Esto es suficiente para la gran mayoría de aplicaciones de consumo y profesionales, sobre todo cuando se puede escalar la frecuencia del reloj. Además, la fabricación de tarjetas con GDDR es más sencilla y barata, porque se utiliza una PCB convencional sin necesidad de interposers ni encapsulados tan complejos. Esto facilita a los usuarios la posibilidad de ampliar la memoria RAM en tu PC.
En cambio, la memoria HBM se encuentra dentro del encapsulado de la GPU, apilada verticalmente junto al chip de cálculo sobre un interposer de silicio. Esto permite buses de miles de bits (5120, 8192, etc.), lo que se traduce en un ancho de banda enorme incluso con frecuencias moderadas. A nivel de eficiencia energética por bit transferido, HBM suele salir claramente ganadora frente a GDDR.
Sin embargo, HBM tiene una contrapartida importante: la cantidad de memoria total no es tan fácil de escalar. Como las pilas están integradas en el propio paquete de la GPU, no se puede simplemente “añadir más chips” en la PCB como se haría con GDDR. Esto hace que la configuración de memoria sea menos flexible y que cada diseño de GPU con HBM requiera una ingeniería muy específica desde el principio.
Ventajas y desventajas prácticas de usar memoria HBM
Las memorias HBM presentan una serie de ventajas muy claras para determinadas aplicaciones, pero también algunos inconvenientes que explican por qué no se han extendido al mercado gaming de forma masiva.
Elimina cuellos de botella de ancho de banda
Al estar situadas en el mismo encapsulado que la GPU o la CPU, las pilas HBM se conectan mediante rutas de señal muy cortas y anchas, apoyadas en el interposer de silicio. Esto permite reducir la latencia y aumentar el ancho de banda efectivo, evitando cuellos de botella que sí aparecen cuando la memoria está más alejada físicamente en la PCB.
Para cargas de trabajo que mueven cantidades gigantescas de datos (como modelos de IA con miles de millones de parámetros, simulaciones científicas complejas o análisis en tiempo real), disponer de un bus de memoria tan brutal marca la diferencia entre una GPU que se pasa el día esperando datos y otra que puede mantener las unidades de cálculo ocupadas casi constantemente.
Mayor eficiencia energética
La filosofía de HBM de combinar un bus muy ancho con frecuencias moderadas tiene una consecuencia directa: mejor eficiencia energética por bit transferido. Al requerir menos tensión y menos frecuencia para lograr el mismo o mayor ancho de banda que GDDR, el consumo total de la memoria se reduce de manera notable. En equipos domésticos, medidas para acelerar un PC con poca memoria RAM suelen ser opciones prácticas.
Además, como se necesitan menos chips de memoria para alcanzar un determinado nivel de rendimiento, se ahorra espacio y se disminuyen las pérdidas eléctricas que aparecen en rutas de señal más largas y complejas. Esto es especialmente valioso en entornos de centros de datos, donde cada vatio extra supone un coste recurrente en energía y refrigeración.
Factor de forma mucho más compacto
Otra ventaja muy importante de HBM es el reducción drástica del espacio físico ocupado por la memoria. Al apilar las matrices verticalmente y colocarlas sobre el interposer junto a la GPU, se consigue que todo el subsistema de memoria ocupe una superficie muy pequeña en comparación con disponer una docena o más de chips GDDR alrededor del procesador.
En términos prácticos, para una misma cantidad de memoria en una tarjeta gráfica, HBM puede llegar a ocupar hasta un 90 % menos de superficie que configuraciones equivalentes con GDDR5/GDDR6. Esto permite diseñar PCB más pequeñas, dejar más espacio para otros componentes o simplemente simplificar el trazado de pistas y la alimentación de la tarjeta.
Costes de fabricación elevados
El gran hándicap de HBM es el coste. Fabricar obleas de DRAM pensadas para apilamiento 3D con TSV, montar las pilas, producir el interposer de silicio y encapsularlo todo junto con la GPU requiere procesos de fabricación mucho más complejos y caros que soldar chips GDDR en una PCB.
Se estima que las obleas destinadas a HBM pueden costar entre un 30 y un 50 % más que las de DRAM convencionales. A esto hay que sumar el coste adicional del propio interposer y de los pasos extra de ensamblaje. Como resultado, las GPU con HBM suelen situarse en segmentos de precio muy altos, reservados para centros de datos, estaciones de trabajo de gama extrema o supercomputadores.
Un ejemplo claro fue la familia AMD Radeon Vega, que utilizó HBM2. Aunque el ancho de banda de memoria era excelente, el coste añadido condicionó el precio final de las tarjetas, lo que dificultó competir con soluciones gaming basadas en GDDR que ofrecían una relación rendimiento/precio más atractiva para el usuario doméstico.
Aplicaciones típicas de HBM frente a GDDR
Por todo lo anterior, la elección entre GDDR y HBM depende en gran medida del tipo de carga de trabajo para el que vaya destinada la GPU.
Las GPU equipadas con memoria GDDR suelen ser más accesibles y se enfocan en el mercado de consumo y profesional generalista. Son más baratas de fabricar porque la memoria se monta directamente en la PCB, y para la mayoría de aplicaciones (juegos, edición de vídeo, visualización 3D, etc.) el ancho de banda que ofrecen GDDR6 o GDDR6X es más que suficiente.
En cambio, las GPU con memoria HBM son productos de nicho orientados sobre todo a HPC (High Performance Computing), IA a gran escala y cargas de trabajo científicas que necesitan exprimir el ancho de banda al máximo. Aquí el coste pasa a un segundo plano frente a la necesidad de reducir tiempos de entrenamiento de modelos, acelerar simulaciones o servir inferencias a millones de usuarios simultáneos.
Un caso muy visible es el de los modelos de IA generativa como los que se utilizan para chatbots avanzados y sistemas de recomendación. Implementaciones basadas en miles de GPU con HBM, como las granjas de aceleradores NVIDIA H100, permiten procesar en tiempo real las peticiones de millones de usuarios. Sin esa combinación de gran potencia de cálculo y memoria de altísimo ancho de banda, ofrecer este tipo de servicios a gran escala sería inviable o excesivamente lento.
En el ámbito profesional más “tradicional”, GPU de gama alta con GDDR, como las basadas en arquitecturas orientadas a estaciones de trabajo, siguen siendo una opción muy sólida para entrenamiento de modelos medianos, renderizado, simulación y análisis de datos cuando las cargas se pueden paralelizar entre varias tarjetas y no requieren el ancho de banda extremo que aporta HBM.
En conjunto, la memoria HBM se ha consolidado como la solución ideal cuando el ancho de banda y la eficiencia energética son críticos y el presupuesto lo permite, mientras que GDDR mantiene su reinado en el mercado masivo gracias a su equilibrio entre coste, rendimiento y flexibilidad. Todo indica que, a corto y medio plazo, ambas tecnologías seguirán coexistiendo: HBM impulsando la punta de lanza de la supercomputación y la IA, y GDDR cubriendo la inmensa mayoría de GPUs de consumo y profesionales generalistas.
